վ����ϵ��
վ����ϵ��
�������˹����ܼ������ͻ����ʱ���������ģ AI ѵ����Ϊ�ƶ���ҵ���ĺ������档Ȼ������ͳ����ܹ������ǧ�ڼ��������ڼ�����ģ��ѵ��ʱ������¶������ƿ�����ܺĸ����Լ���̬�����Բ�������⡣���գ��˳������������һ����ȫ�ɿ�AI ������ CS5698H3���Ը����ܡ����ġ����żܹ����ص㣬Ϊ�����ģ AI ѵ���������Ч�����š���ɫ��ȫ��ƽ̨��

�����������ܱ���
����CS5698H3���� 2 �ŵ��Ĵ� C86 �������� 8 �� OAM ģ�飬ʵ�ּ������ܵĿ�Խʽ�����������ݴ��䷽�棬֧�� 896GB/s �� GPU ����������ʹ�������ڸ����㵥Ԫ�����תѸ�٣���Ⱥ��չ�����ﵽ3.2Tbps��Ϊ���ģ�ֲ�ʽѵ���ṩ�˼�ʵ�Ĵ������ϡ�ͨ��ʵ�ʲ�����֤��CS5698H3�ڴ��ģѵ�������еļ��ٱȳ�90%���ܹ��������ģ��ѵ�����ڣ�����������������ҵӦ�õ�Ч�ʡ�
�������⣬CS5698H3 �䱸 8*NVMe SSD ���ݻ������ģ�飬��Ը�����ѵ������Ԥ�����������ṩ�˸�Ч�����ݴ洢���ȡ����������ڴ�������ѵ������ʱ��SSD �ĸ��ٶ�д�����ܹ�������Ӧ�������������ݴ����Ϊ����ƿ����ȷ������ѵ�����̵������ԡ�
������ɫ��Чͻ��
������ȫ����ɫ��̼��չ�ı����£��������ĵ��ܺ����������ܵ���ע���˳� CS5698H3 ����Ч�Ż�����ʵ�ֲ�ƷȫҺ����Ƹ��� 80% ���Ϲؼ�������ͨ��Һ����ȴ���ʵĸ�Ч�ȴ������ԣ��ܹ�Ѹ�ٴ��ߴ�������GPU �Ⱥ��IJ��������й����в����Ĵ�����������ȴ�ͳ����ɢ�ȷ�ʽ��Һ�似������ɢ��Ч�ʸ��ߣ�������������ɢ��ϵͳ��������Ϊ��������Ӫ�찲�������л�����
�������ڴ��ģ�������Ķ��ԣ�ÿ���� 0.1 ��PUEֵ����Դʹ��Ч�ʣ�������ζ�ž�ĵ�ѽ�ʡ��̼�ŷż��٣�CS5698H3��PUEֵ����1.15��������ҵ����ˮƽ��ͬʱ��ͨ����ɢ��ϵͳ���Ż���ƣ���Ʒʵ����20%����Ч��������������������ĵ�̼������Ҫ��CS5698H3 ����ɫ��Ч��������Ϊ�������ĵĿɳ�����չ�ṩ������֧�š�
�������żܹ�����
�����˳���������ֿ��ŵ���������ڴ����Ԫ���ŵ� AI ������̬��CS5698H3֧�ֹ������� NPU/GPGPU �ܹ�оƬ��ͨ�� Scale-out ��ڵ�ֱ�������� 8+1 NDR/RoCE ���磬�ܹ�ʵ�ֶ�Ԫ�칹оƬ�ļ�Ⱥ�����𣬳�ַ��Ӳ�ͬоƬ���������ƣ������������ AI ��������
�����ڸ���ͨ����·���棬CS5698H3 ����ȫ PCIe 5.0 ������·������������ PCIe 4.0 ���������ܹ�Ϊ���Դ桢�ߴ��� AI оƬ�ṩ��������ݴ������������ǧ��ģ��ѵ�����������������Ͽ�Ҫ������������Ȼ���Դ�����NLP����������Դ�ģ��ѵ���������ڶ�ģ̬�����ͼ�����ı�����ѵ����CS5698H3 ����ƾ���俪�żܹ������ͨ��������Ϊ�������ṩ�ȶ�����Ч�ļ���ƽ̨��
�����ೡ��Ӧ�ø���
�����ڳ����ģģ��ѵ������CS5698H3 ƾ��ǿ��ļ���������ߴ������ݴ����������ܹ�֧�����ڲ���ģ�͵ķֲ�ʽѵ������ NLP ���������Լ�������ģ�͵�ѵ�����̣��������ܿͷ������������Ӧ�õĿ��ٷ�չ���ڶ�ģ̬�����ܹ�Ϊͼ�����ɡ���Ƶ�����ǰ�ؼ������о��ṩ��ʵ�ļ��������
���������������Ļ������ԣ�CS5698H3Һ��ܹ����ص㲻���������������ĵ��ܺģ�������Ч�����豸�Ĺ����ʣ��ӳ�Ӳ��ʹ���������Ӷ��������� TCO����ӵ�гɱ��������ŵļܹ�Ҳ�����������豸���м�����Эͬ�������������ĵ���������������ԡ�
��������ҵ AI ���ܷ��棬CS5698H3 ���ݹ���оƬ��̬�����ԣ�������ҽ�ơ����������ר��ģ�Ϳ���������ѡ���������������ڹ������ܾ���ϵͳ����ҽ�������ܹ�����ҽѧӰ�����������Ԥ���ģ�͵�ѵ����������������������ʵ�������ʼ졢�����Ż���Ӧ�ó������ƶ�����ҵ�����ܻ�ת�͡�
�����˳��������ȫ�ɿ� AI ������ CS5698H3 �Լ������ܡ���ɫ��Ч�����żܹ��㷺��Ӧ�������ԣ�ΪAI����Ӧ���ṩ��Ӧ��ƽ̨��Ϊ��ҵ��չע�����µĻ��������� AI �����������ˮƽ��



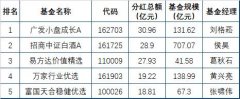
��2024����ڽ�������������֮�ʣ�������ձ����ֹ�˾

Ϊ��������������ڹ������龫��,��һ�������ҵ��

�����������ӻ��ȸ��ֿƼ���Ѹ�ͷ�չ�����Ǵ���������